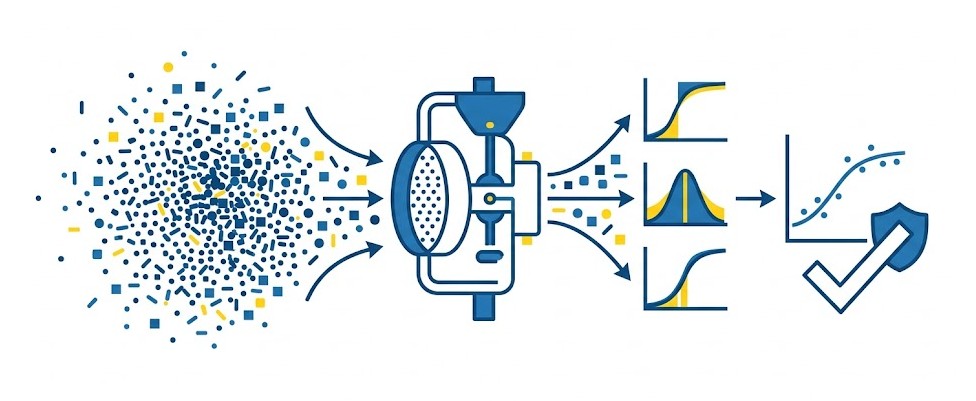
L'action copulaFit offre deux voies majeures via le paramètre method : l'approche MLE (Maximum Likelihood EstimationLa Maximum Likelihood Estimation (MLE) est une méthode statistique qui sélectionne les paramètres d'un modèle maximisant la probabilité (vraisemblance) que les données observées se produisent.) et l'approche CAL (CalibrationAjustement des paramètres d’un modèle pour aligner les probabilités prédites sur les fréquences observées, garantissant que le score reflète la probabilité réelle de l'événement dans les données.). La méthode par calibrationAjustement des paramètres d’un modèle pour aligner les probabilités prédites sur les fréquences observées, garantissant que le score reflète la probabilité réelle de l'événement dans les données. est particulièrement utile pour générer rapidement des valeurs initiales fiables pour les copules archimédiennesClasse de copules construites via une fonction génératrice $\phi$. Elles simplifient la modélisation de dépendances multidimensionnelles complexes en réduisant le calcul à une dimension..
Pour garantir la convergence mathématique de la vraisemblance, le bloc optimizer donne accès à des solveurs non linéaires de pointe. Le choix par défaut est la méthode de Newton-RaphsonMéthode itérative utilisée dans SAS Viya pour trouver les racines d'une fonction ou maximiser la vraisemblance. Elle converge rapidement en utilisant la dérivée et la courbure (Hessienne) locale. avec recherche linéaire (NEWTONRAPHSONWITHLINESEARCH), mais des alternatives comme TRUSTREGION ou DOUBLEDOGLEG sont disponibles. L'ajustement ultra-fin s'opère via des critères de tolérance stricts tels que le gradient absolu (agtl) ou la différence de fonction relative (ftol).