Si vous avez l’habitude de travailler avec SAS et HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. vous avez sans doute été confronté, au moins une fois, au problème des 32K, The «32k string thing» comme vous pourriez le lire sur internet, notamment sur communities.sas.com. On doit d’ailleurs ce nom à Jeff Bailey.
")
")
") Au passage, examinons au passage la structure de la table pour vérifier le type de données de notre colonne « à problème » et la « vision » SAS, via une proc content :
Au passage, examinons au passage la structure de la table pour vérifier le type de données de notre colonne « à problème » et la « vision » SAS, via une proc content :
") Nous constatons que notre variable chaine, de type texte, « consomme » 32767 octets :
Nous constatons que notre variable chaine, de type texte, « consomme » 32767 octets :
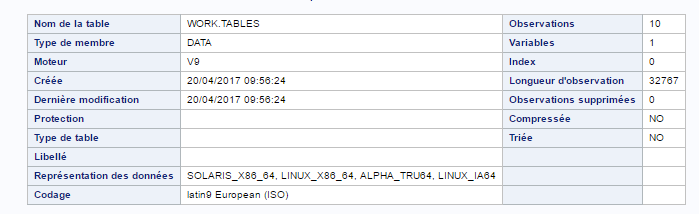
") La volumétrie de la table, côté SAS, est de 520 ko :
La volumétrie de la table, côté SAS, est de 520 ko :
") Avant de continuer, un point rapide s'impose :
Puis vérifions la nouvelle structure de la table :
Avant de continuer, un point rapide s'impose :
Puis vérifions la nouvelle structure de la table :
") Et pour terminer, vérifions dans SAS :
Code :
Journal :
Et pour terminer, vérifions dans SAS :
Code :
Journal :
") Proc content :
Proc content :") Le dataset SAS n'occupe maintenant plus que 160 ko contre 520 ko avant l'ajout de la propriété :
Le dataset SAS n'occupe maintenant plus que 160 ko contre 520 ko avant l'ajout de la propriété :
") ATTENTION : Il est important de bien définir la valeur de la propriété SASFMT afin de ne pas obtenir des valeurs tronquées !
Exemple de données avec SASFMT positionnée à 100 :
ATTENTION : Il est important de bien définir la valeur de la propriété SASFMT afin de ne pas obtenir des valeurs tronquées !
Exemple de données avec SASFMT positionnée à 100 :
") Exemple de données avec SASFMT positionné à 10 :
Exemple de données avec SASFMT positionné à 10 :
") Sources et autres documentations :
Problem Note 63952: Queries of HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. tables return "WARNING: The following column could have a length in SAS of 32767..." and cause performance problems
Data Types for HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. > Issues When Converting Data from Hive to SAS
SAS/ACCESS to HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. et les champs STRING : WARNING ou ERROR ?
Sources et autres documentations :
Problem Note 63952: Queries of HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. tables return "WARNING: The following column could have a length in SAS of 32767..." and cause performance problems
Data Types for HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. > Issues When Converting Data from Hive to SAS
SAS/ACCESS to HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. et les champs STRING : WARNING ou ERROR ?
Le constat
Vous travaillez avec des données stockées dans un clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data., ce qui n’est pas un problème mais plutôt un excellent choix. Vous copiez vos données de ce clusterEnsemble de nœuds (machines) interconnectés, gérés par Kubernetes, qui collaborent pour exécuter les microservices et le moteur CAS de SAS Viya, assurant haute disponibilité et passage à l'échelle. vers SAS (dans votre work par exemple) et vous vous retrouvez rapidement avec des problèmes d’espace, pouvant aller jusqu’à la saturation de la Work . En effet, après rapatriement et malgré la faible volumétrie de vos données HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data., l’espace occupé, côté SAS, est disproportionné. D’ailleurs, si vous prêtez attention au warning présent dans votre journal SAS vous constatez le message suivant : WARNING: SAS/ACCESS assigned this column a length of 32767. If the resulting SAS character variable remains this length, SAS performance is impacted. [Update avril 2019] Il est possible de remplacer le WARNING par un ERROR en suivant les instructions de la note http://support.sas.com/kb/63/952.htmlLe problème
L’impact n’est pas négligeable. En effet, l’une des particularités d’HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. est de travailler avec des volumétries de données importantes. Si vos données HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. contiennent de nombreuses colonne typées String et des nombreuses données, l’espace nécessaire côté SAS peut rapidement devenir problématique. En effet, une table n’occupant que 300 MO peut faire 30 go une fois rapatrié dans SAS. ce point est documenté ici : Issues When Converting Data from Hive to SAS
Au passage, examinons au passage la structure de la table pour vérifier le type de données de notre colonne « à problème » et la « vision » SAS, via une proc content :
Nous constatons que notre variable chaine, de type texte, « consomme » 32767 octets :
La volumétrie de la table, côté SAS, est de 520 ko :
- Si la table est créé via SAS , depuis un dataset SAS et via de l'IMPLICIT PASS-THROUGH, les propriétés de table seront bien positionnées côté HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data.. Pas de problème 32K
- Si la table est créé via SAS (depuis un dataset SAS et via de l'EXPLICIT PASS-THROUGH, aucune propriété SASFMT ne sera créé côté HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data.. Problème 32K
- Avec une table créé « en dehors de SAS » (via HUE ou à partir d'un fichier plat), il est nécessaire de faire un ALTER TABLE pour ajouter la propriété de table SASFMT. Problème 32K
Comment appliquer l'option SASFMT sur une table existante ?
Pour spécifier une limite pour une colonne STRING individuelle, utiliser une instruction Hive ALTER TABLE limitant la longueur de la colonne. Exemple :1
alter table tableS set tblproperties ('SASFMT:chaine'='CHAR(1000)');
Et pour terminer, vérifions dans SAS :
Code :
1
2
3
2
3
data work.tableS;
set myhadoop.tableS;
run;
set myhadoop.tableS;
run;
Proc content :
Le dataset SAS n'occupe maintenant plus que 160 ko contre 520 ko avant l'ajout de la propriété :
Exemple de données avec SASFMT positionné à 10 :
Sources et autres documentations :
Problem Note 63952: Queries of HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. tables return "WARNING: The following column could have a length in SAS of 32767..." and cause performance problems
Data Types for HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. > Issues When Converting Data from Hive to SAS
SAS/ACCESS to HadoopFramework open-source permettant le stockage distribué (HDFS) et le traitement de données massives sur des clusters de serveurs, souvent utilisé avec SAS Viya pour l'analyse Big Data. et les champs STRING : WARNING ou ERROR ?



")







{kind=link}